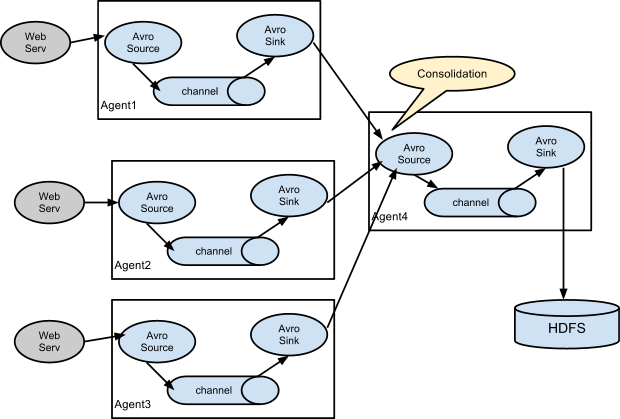
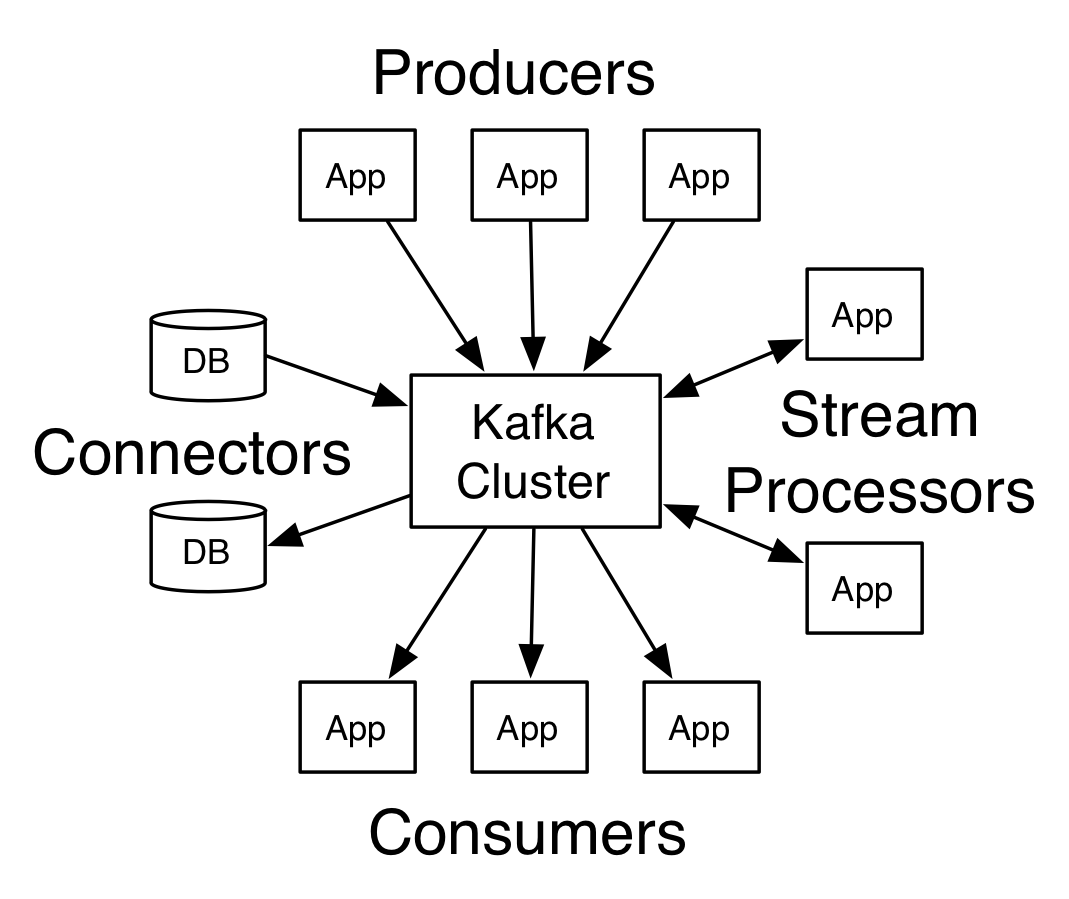
我对你的敬仰犹如滔滔江水连绵不绝,又如黄河泛滥一发不可收拾。 – 周星驰
流处理概述 环境配置 参考spark-sql中的环境配置 ,目录结构同上,jdk和spark版本升级如下:
jdk:1.8
实时流处理框架和架构
Strom: 真实时,来一条处理一条
Spark Streaming: 基于自定义时间间隔(2s,3s)的批量处理。微批处理
Kafka:国内使用较少
Flink:离线批处理 + 实时
为什么要将Flume收集的日志放入Kafka而不是直接丢给实时处理系统?
一般情况下业务有高峰期和低峰期,高峰期如果大量日志直接命中实时流处理系统,流处理系统可能扛不住压力,所以一般情况下会加一层MQ用来缓冲。
实时流处理的应用 电信行业,如果用户流量快用完的时候发短信订购流量包
大数据分析可以提高转化率。
分布式日志收集框架Flume 解决什么问题
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
有多台服务器上运行着我们的应用程序,各个机器上有os日志,web server日志,application的日志。假设我们需要将这些日志要收集到hadoop集群上就需要定时执行scp。实时性和容错性得不到保证,文本文件的格式一般需要压缩传输。这些问题flume都帮我们解决了。只需要配置文件就OK了。类似框架还可以使用LogStash。
架构和核心组件
source:采集
环境部署 下载解压,配置系统环境变量:
1 2 export FLUME_HOME=/home/hadoop/app/apache-flume-1.6.0-cdh5.7.6-binPATH=$FLUME_HOME /bin:$PATH
配置文件在conf目录下,cp flume-env.sh.template flume-env.sh,导出$JAVA_HOME.
从指定端口收集数据到控制台 一个简单的例子
a1:agent的名称
example.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop001 a1.sources.r1.port = 44444 a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
1 flume-ng agent --conf $FLUME_HOME /conf --conf-file $FLUME_HOME /conf/example.conf --name a1 -Dflume.root.logger=INFO,console
使用telnet连接到hadoop001 44444并发送数据,可以看到agent输出。
1 (SinkRunner-PollingRunner-DefaultSinkProcessor) [INFO - org.apache.flume.sink.LoggerSink.process(LoggerSink.java:94)] Event: { headers:{} body: 68 65 6C 6C 6F 0D hello. }
Event是Flume数据传输的基本单环,Event = 可选的header + byte array
实时监控文件采集新增数据到控制台 agent选型:exec source + memory channel + logger sink
example.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -F /home/hadoop/data/data.log a1.sources.r1.shell = /bin/sh -c a1.sinks.k1.type = logger a1.channels.c1.type = memory a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
将A服务器上的日志实时采集到B服务器
exec source + memory channel + avro sink
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 exec-memory-avro.sources = exec-source exec-memory-avro.sinks = avro-sink exec-memory-avro.channels = memory-channel exec-memory-avro.sources.exec-source.type = exec exec-memory-avro.sources.exec-source.command = tail -F /home/hadoop/data/data.log exec-memory-avro.sources.exec-source.shell = /bin/sh -c exec-memory-avro.sinks.avro-sink.type = avro exec-memory-avro.sinks.avro-sink.hostname = hadoop001 exec-memory-avro.sinks.avro-sink.port = 44444 exec-memory-avro.channels.memory-channel.type = memory exec-memory-avro.sources.exec-source.channels = memory-channel exec-memory-avro.sinks.avro-sink.channel = memory-channel avro-memory-logger.sources = avro-source avro-memory-logger.sinks = logger-sink avro-memory-logger.channels = memory-channel avro-memory-logger.sources.avro-source.type = avro avro-memory-logger.sources.avro-source.bind = hadoop001 avro-memory-logger.sources.avro-source.port = 44444 avro-memory-logger.sinks.logger-sink.type = logger avro-memory-logger.channels.memory-channel.type = memory avro-memory-logger.sources.avro-source.channels = memory-channel avro-memory-logger.sinks.logger-sink.channel = memory-channel
消息队列Kafka 架构及核心概念
每一条消息记录由key,value和timestamp组成。topic用于给消息记录打标签,消费者可以按照指定的标签进行消费。
部署和使用 先安装zookeeper,配置$ZK_HOME。cp zoo_sample.cfg zoo.cfg,配置dataDir=/home/hadoop/app/tmp/zk。
使用./zkServer.sh start启动服务器之后就可以使用./zkCli.sh连接到服务器。zk-cli命令ls / ,ls /zookeeper。
kafka版本kafka_2.11-0.9.0.0,下载解压并配置KAFKA_HOME。
单节点单broker config/server.properties
1 2 3 4 broker.id=0 listeners=PLAINTEXT://:9092 log.dirs=/home/hadoop/app/tmp/kafka-logs zookeeper.connect=hadoop001:2181
1 2 3 4 5 6 7 8 9 10 11 12 13 14 kafka-server-start.sh /home/hadoop/app/kafka_2.11-0.9.0.0/config/server.properties kafka-topics.sh --create --zookeeper hadoop001:2181 --replication-factor 1 --partitions 1 --topic hello_topic kafka-topics.sh --list --zookeeper hadoop001:2181 kafka-console-producer.sh --broker-list hadoop001:9092 --topic hello_topic kafka-console-consumer.sh --zookeeper hadoop001:2181 --topic hello_topic --from-beginning kafka-topics.sh --describe --zookeeper hadoop001:2181
启动生产者和消费者之后就可以在生产者所在tty发送消息了,从而消费者可以收到消息。上面的cmd中消费者加了参数--from-beginning,消费者重启之后以前的消息会再次收到。
单节点多broker 在单台服务器上配置多台kafka。
将server.properties复制为server-1.properties,server-2.properties,server-3.properties并修改对应的broker.id,listeners,log.dirs
1 2 3 4 5 6 7 8 kafka-server-start.sh -daemon $KAFKA_HOME /config/server-1.properties & kafka-server-start.sh -daemon $KAFKA_HOME /config/server-2.properties & kafka-server-start.sh -daemon $KAFKA_HOME /config/server-3.properties & kafka-topics.sh --create --zookeeper hadoop001:2181 --replication-factor 3 --partitions 1 --topic my-replicated-topic kafka-console-producer.sh --broker-list hadoop001:9093,hadoop001:9094,hadoop001:9095 --topic my-replicated-topic kafka-console-consumer.sh --zookeeper hadoop001:2181 --topic my-replicated-topic
容错性测试 1 2 3 [hadoop@hadoop001 my-replicated-topic-0]$ kafka-topics.sh --describe --zookeeper hadoop001:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
上面的描述信息显示1号broker是主,现在使用kill -9干掉2号(pid可以使用jps -m查看)
1 2 3 [hadoop@hadoop001 my-replicated-topic-0]$ kafka-topics.sh --describe --zookeeper hadoop001:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 1 Replicas: 1,2,3 Isr: 1,3
Isr中2不见了。接下来干掉1号broker。可以发现消费者终端中出现了warning,但是发的消息还是可以收到。
1 2 3 [hadoop@hadoop001 my-replicated-topic-0]$ kafka-topics.sh --describe --zookeeper hadoop001:2181 --topic my-replicated-topic Topic:my-replicated-topic PartitionCount:1 ReplicationFactor:3 Configs: Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 1,2,3 Isr: 3
Leader由1变成了3,因此只要有一个broker正常就可以了。
Kafka高级特性 消息事务 为什么要支持事务?满足:“读取-处理-写入”模式。
数据传输的事务定义:
最多一次:消息不会被重复发送,最多被传输一次(可能一次也不传输)
Kafka保证事务的机制:
内部重试:Producer幂等处理
多分区原子写入
避免僵尸实例
零拷贝 java nio中的channel.transforTo()方法,底层系统调用是sendfile。将磁盘上的一个文件块发送到网络上需要经过这样的几步:
OS将数据从磁盘读入到内核空间的页缓存
应用程序将数据从内核空间读入到用户空间的缓存中
应用程序将数据写回到内核空间的socket缓存中
OS将数据从socket缓冲区复制到网卡缓冲区,以便将数据发送出去
以上数据经过了4次拷贝,如果采用零拷贝机制则只有以下几步:
OS将数据从磁盘读入到内核空间的页缓存
将数据的位置和长度信息的描述符增加内核空间(socket缓冲区)
OS将数据从内核拷贝到网卡缓冲区,以便将数据经过网络发出
数据只经过了2次拷贝!零拷贝指的是:内核空间和用户空间之间的拷贝次数是0。
整合Flume完成数据采集
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 avro-memory-kafka.sources = avro-source avro-memory-kafka.sinks = kafka-sink avro-memory-kafka.channels = memory-channel avro-memory-kafka.sources.avro-source.type = avro avro-memory-kafka.sources.avro-source.bind = hadoop001 avro-memory-kafka.sources.avro-source.port = 44444 avro-memory-kafka.sinks.kafka-sink.type = org.apache.flume.sink.kafka.KafkaSink avro-memory-kafka.sinks.kafka-sink.brokerList = hadoop001:9092 avro-memory-kafka.sinks.kafka-sink.topic = hello_topic avro-memory-kafka.sinks.kafka-sink.batchSize = 5 avro-memory-kafka.sinks.kafka-sink.requiredAcks = 1 avro-memory-kafka.channels.memory-channel.type = memory avro-memory-kafka.sources.avro-source.channels = memory-channel avro-memory-kafka.sinks.kafka-sink.channel = memory-channel
1 2 flume-ng agent --conf $FLUME_HOME /conf --conf-file $FLUME_HOME /conf/avro-memory-kafka.conf --name avro-memory-kafka -Dflume.root.logger=INFO,console flume-ng agent --conf $FLUME_HOME /conf --conf-file $FLUME_HOME /conf/exec-memory-avro.conf --name exec-memory-avro -Dflume.root.logger=INFO,console
Spark-Streaming环境搭建 下载scala2.11.8配置$SCALA_HOME环境变量。
Hbase的配置 配置$HBASE_HOME系统变量。
修改conf/hbase-env.sh中的JAVA_HOME并设置HBASE_MANAGES_ZK=false。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 <property > <name > hbase.rootdir</name > <value > hdfs://hadoop001:8020/hbase</value > </property > <property > <name > hbase.cluster.distributed</name > <value > true</value > </property > <property > <name > hbase.zookeeper.quorum</name > <value > hadoop001:2181</value > </property > <property > <name > hbase.zookeeper.property.dataDir</name > <value > /home/hadoop/app/tmp</value > </property >
修改conf/regionservers为hadoop001。
启动bin/start-hbase.sh,WebUI地址http://hadoop001:60010。
启动hbase客户端
1 2 3 4 5 6 ./bin/hbase shell version status create 'member' ,'info' ,'address' list describe 'member'
Spark-Streaming核心概念和编程 入门 one stack to rule them all.一栈式解决。
官网的例子
使用spark-submit提交(生产)
1 2 3 nc -lk 9999 spark-submit --master local [2] --class org.apache.spark.examples.streaming.NetworkWordCount --name NetworkWordCount /home/hadoop/app/spark-2.2.0-bin-2.6.0-cdh5.7.0/examples/jars/spark-examples_2.11-2.2.0.jar hadoop001 9999
使用spark-shell提交(开发)
1 spark-shell --master local [2]
将下面的代码粘贴到spark-shell中即可:
1 2 3 4 5 6 7 8 import org.apache.spark.streaming.{Seconds , StreamingContext }val ssc = new StreamingContext (sc, Seconds (1 ))val lines = ssc.socketTextStream("hadoop001" , 9999 )val words = lines.flatMap(_.split(" " ))val wordCounts = words.map(x => (x, 1 )).reduceByKey(_ + _)wordCounts.print() ssc.start() ssc.awaitTermination()
Spark Streaming接收到实时数据流,把数据按照指定时间段切成一片片的小数据块,把小数据块交给SparkEngine处理。
Spark应用程序运行在Driver端,Driver端会要求Executor启动一些接收器,Receiver启动之后会将InputStream拆分成小的Block存放在内存中(如果设置了多副本的话还会拷贝到其他机器),之后Receiver会将block信息高速StreamingContext,每隔指定的时间周期StreamingContext会通知SparkContext应该启动一些jobs了,接下来SparkContext将jobs分发到Executor执行。
DStreams:
Discretized Streams (DStreams): a DStream is represented by a continuous series of RDDs, a DStream is represented by a continuous series of RDDs, which is Spark’s abstraction of an immutable, distributed dataset.
InputStreams & Receivers:
Every input DStream (except file stream, discussed later in this section) is associated with a Receiver (Scala doc, Java doc) object which receives the data from a source and stores it in Spark’s memory for processing.
处理Socket数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 object NetworkWordCount def main Array [String ]) { val sparkConf = new SparkConf ().setMaster("local[2]" ).setAppName("NetworkWordCount" ) val ssc = new StreamingContext (sparkConf, Seconds (5 )) val lines = ssc.socketTextStream("localhost" , 6789 ) val result = lines.flatMap(_.split(" " )).map((_, 1 )).reduceByKey(_ + _) result.print() ssc.start() ssc.awaitTermination() } }
处理文件数据 1 2 3 4 5 6 7 8 9 10 11 12 13 object FileWordCount def main Array [String ]) { val sparkConf = new SparkConf ().setMaster("local" ).setAppName("FileWordCount" ) val ssc = new StreamingContext (sparkConf, Seconds (5 )) val lines = ssc.textFileStream("file:///tmp/ss" ) val result = lines.flatMap(_.split(" " )).map((_, 1 )).reduceByKey(_ + _) result.print() ssc.start() ssc.awaitTermination() } }
window:定时进行一个时间段内的数据处理。